中國人工智能產業迎來了一個重要里程碑 —— 全國已備案的大模型數量正式突破 400 款。這一成就不僅標志著我國在人工智能技術領域的持續發力和規模化發展,更反映出大模型從實驗室走向實際應用、推動社會各領域變革的堅定步伐。以下從發展歷程、區域格局、產業生態及未來展望幾個維度展開深入分析:
技術積累與創新迭代近年來,中國科技企業、科研機構和高校在大模型研發上持續投入,算法優化、算力提升和數據處理能力不斷突破瓶頸。從早期通用大模型如百度 “文心一言”、阿里 “通義千問”、華為 “盤古” 等頭部產品引領技術探索,到如今垂直領域模型百花齊放,如醫療診斷、工業質檢、金融風控等細分場景模型層出不窮,技術自主創新能力顯著增強。開源社區的活躍也加速了技術擴散 —— 許多初創企業基于開源基座模型(如 DeepSeek 等)進行二次開發,降低了研發門檻,推動了備案數量的激增。
政策引導與合規護航國家對人工智能產業的發展始終秉持 “發展與安全并重” 原則。自《生成式人工智能服務管理暫行辦法》等法規出臺后,大模型備案成為企業合規提供服務的必要前提。備案機制不僅強化了內容安全審核、數據隱私保護和算法透明性要求,還通過前置準入 + 事中監管 + 事后追溯的全鏈條治理,規范行業秩序,為產業健康發展筑牢底線。這種制度設計既防范了潛在風險(如虛假信息生成、惡意應用等),又為真正有技術實力和社會價值的模型開辟了商業化通道。
場景需求與落地驅動實體經濟的數字化轉型需求是大模型規模化備案的根本動力。在制造業,AI 質檢模型提升良品率;在金融領域,智能客服和風險預測模型優化服務效率;政務領域的智能問答系統提升民生服務便捷性;教育場景的個性化學習助手推動因材施教…… 越來越多的企業認識到,脫離實際場景的大模型難以形成商業閉環。因此,備案模型中行業專用型(L1)占比逐步提升,體現出從 “炫參數” 向 “重實效” 的務實轉變。
全國備案大模型呈現出顯著的梯隊化城市分布和區域協同發展態勢:
頭部城市引領創新高地
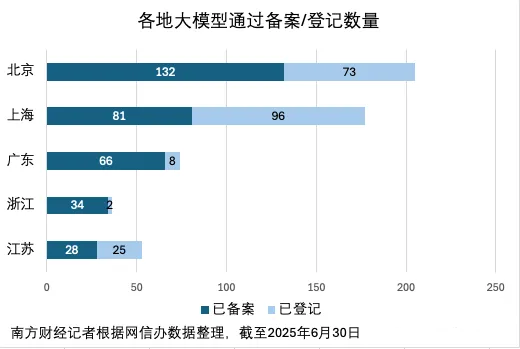
- 北京(超 140 款):作為國家級 AI 創新核心樞紐,依托頂尖高校、央企和科研平臺,在通用模型、基礎研究及全領域垂直應用上占據主導地位,覆蓋互聯網、政務、金融等全鏈條場景。
- 上海(超 80 款):聚焦國際化生態與跨境數據應用,尤其在金融科技、智能制造、傳媒娛樂等垂類模型優勢突出,浦東數據交易所等平臺進一步強化其資源整合能力。
- 廣深杭及長三角城市群:廣州依托傳統企業智能化升級需求,蘇州、南京等長三角城市憑借 “硬件 + 軟件 + 場景” 協同,形成高密度的大模型產業集群;深圳以硬件與機器人、跨境貿易等差異化場景驅動備案增長。
中西部與特色城市的單點突破成都、重慶依托西部算力樞紐與文旅、游戲產業融合探索垂類模型;貴陽、昆明借力 “東數西算” 節點吸引算法企業;廈門、青島等城市圍繞特色產業(如海洋經濟、影視 AIGC)形成創新試點。盡管中西部備案總量占比較小(約 5%),但其差異化路徑正逐步打開區域市場空間。
產業集聚效應凸顯
京津冀、長三角、珠三角三大城市群合計備案占比超 80%,形成 “研發 — 算力 — 應用” 梯度協作:
- 京津冀構建 “北京研發 — 環京算力 — 津冀落地” 鏈條;
- 長三角打造 “上海樞紐 — 杭州 / 蘇州技術外溢” 走廊;
- 珠三角以 “硬件 + 跨境場景” 形成特色競爭力。這種集聚不僅降低了企業間的協作成本,更通過人才流動、技術共享和場景互補,加速了創新生態的繁榮。
備案數量突破 400 款的意義遠超數字本身,折射出產業發展的關鍵轉折:
安全可控成為發展基石
通過備案審核的模型需滿足嚴格的
語料合法性、內容合規性及隱私保護要求(如數據標注規范、關鍵詞攔截機制、用戶數據匿名化等)。這不僅提升了公眾對 AI 服務的信任度,也倒逼企業完善自身治理體系,避免 “帶病上線”,為產業長期健康發展奠定信任基礎。
中小企業參與度顯著提升早期大模型領域被頭部企業主導,但備案機制的完善結合地方政策支持(如多地發放 “模型券”“算力券” 降低使用成本),讓更多中小企業能夠接入或自研輕量級、場景化模型。例如,深圳 24 家中小企業備案近 30 款模型,聚焦智能家居、物流、數字化轉型等細分領域,體現出普惠化發展趨勢。這種生態多元化降低了行業壟斷風險,激發了市場活力。
開源與合作推動技術普惠
越來越多的頭部企業選擇開源策略開放基座模型,中小企業和開發者基于此進行定制化微調(如接入 API 或二次開發),加速了技術擴散與場景創新。例如,TCL、金蝶等企業接入第三方大模型優化自身服務,云天勵飛通過華為 AI 數據湖提升訓練效率 —— 這種合作共贏生態打破了技術壁壘,使 AI 能力真正下沉到生產生活的 “最后一公里”。

 關注微信訂閱號
關注微信訂閱號
